Aside from writing a branding report today (which I will share with you once all contributors have OKed it), I received some wonderful news from Gabriel Weinberg of Duck Duck Go.
Those who are used to the Duck will know that you can search using what he calls bangs—the exclamation mark. On Chrome, which has a minimalist design, I have set my default search engine to Duck Duck Go. But what if I wanted to search on Google?
I can either do what is built in, and what Google suggests, by beginning my typing in the search box with the word Google. Or, I can simply add !g to the end of the query, which, I might add, is something you can do from Duck Duck Go itself, too.
Of course, Google would prefer that I put all searches through them, but having Duck Duck Go as a default isn’t a bad idea.
There’s a huge list of bangs that you can use at the Duck Duck Go website, which include !amazon (which will take you directly to an Amazon.com search), !gn (for Google News—this one is a godsend, especially for Chrome, which has made it much harder to search the news section, even if programmed into the search settings), !video (for YouTube), and !eb or !ebay (for Ebay).
I’m glad to announce that Gabriel has taken on board a few of my suggestions for motoring and fashion publications, such as !autocar, !vogueuk, !jalopnik, !randt (Road and Track) and !lucire (had to get that one in).
We’ll announce this on Lucire shortly, but readers already saw me announce, on Thursday, a nip–tuck of our Newsstand pages. That’s not really news, so I chose to complement it with a few other announcements.
Since we were already fidgeting with that part of the site, Gabriel’s announcement prompted me to do some changes to the search pages, which were woefully out of date.
 The community home page was last designed four years ago, and that time, we just shifted the content over. Never mind that that content was also out of date, and included some letters to the editor that are no longer relevant. It had a link to the old forum, which only results in a PHP error. So today, I had all the old stuff stripped out, leaving us with a fairly minimalistic page.
The community home page was last designed four years ago, and that time, we just shifted the content over. Never mind that that content was also out of date, and included some letters to the editor that are no longer relevant. It had a link to the old forum, which only results in a PHP error. So today, I had all the old stuff stripped out, leaving us with a fairly minimalistic page.
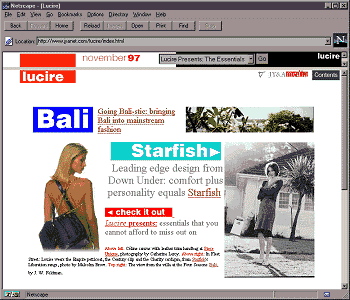
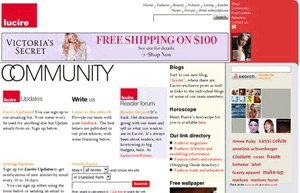
I didn’t plan on making a blog post out of it, so I never took screen shots of the process. But at left is one of the old page from Snap Shots, and long-time readers will recognize this as the website design we had many years ago. When we facelifted other parts of the site, this was left as is: it’s old-fashioned dynamic HTML and hasn’t been moved over to a content-management system.
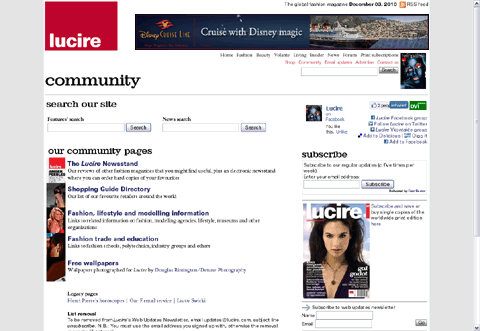
The new one may be a bit sterile (below), but it takes out all the extra bits that very few used: the Swicki, the Flickr gadget (we haven’t added anything to it since 2008), and a complex sign-up form for the Lucire Updates’ service. It’s been stripped to basics, but it now includes the obligatory links to Twitter, Facebook, Vkontakte and the RSS feed.
Which brings us on to the search pages. These also have the updated look, but, importantly, I fixed a bug in the Perl script that kept showing the wrong month. Regardless of whether it was March or December, the script would show January:

This is probably nothing to the actual computer hackers out there, but for a guy who has used an ATM only three times in his entire life (mainly because I lacked the local currency), this is a momentous occasion.
It was one of those evening-tweaking cases where it was simpler for me to do it myself than to ask one of the programmers, and I managed to remedy something that had plagued our website for 10 years.

The searches revealed a few strange links from long-expired pages, and here is where we might get in to a bit of discussion about online publishing.
Once upon a time, it was considered bad form to have dead links, because people might point to them. Even more importantly, because a search engine might, and you could get penalized for having too many.
This is why we’ve kept some really odd filenames. The reason the Lucire Community page is at lucire.com/email is that the link to a free email service we provided at the turn of the century was linked from there. Similarly, we still kept pages called content.htm, contents.shtml and editorial.shtml, even though these pages had not been updated for half a decade.
There are now redirects from these pages, which were once also bad form as far as the search engines were concerned.
But, given that search engines update so much more quickly in 2010, do we still need to bother about these outdated links? Will we still be penalized for having them? Should we not just simply delete them?
If you look to the right of this blog at the RSS feed links, you’ll see some dead ones—there were more, but I have been doing online weeding here, too. It almost seems to be a given that people can remove things without warning and if you encounter a dead link, well, you know how to use a search engine.
To me, it still seems a little on the side of bad manners to do that to your readers, but one might theorize that few care about that any more as many sites revamp on to CMSs to make life easier for themselves.
A side note: earlier this week, when weeding through dead links at Lucire, we noticed that many people had moved to CMSs, with the result that their sites began to look the same. Some put in excellent customizations, but many didn’t. And what is it with all the big type on the news sites and blogs these days? Is this due to the higher resolutions of modern monitors, or do they represent a change in reading habits?
PS.: The search script bug was fixed by changing $month[$mon] to simply $mon. Told you it was nothing, though I noticed that the site that we got the script from still has the bug.—JY
You may also like