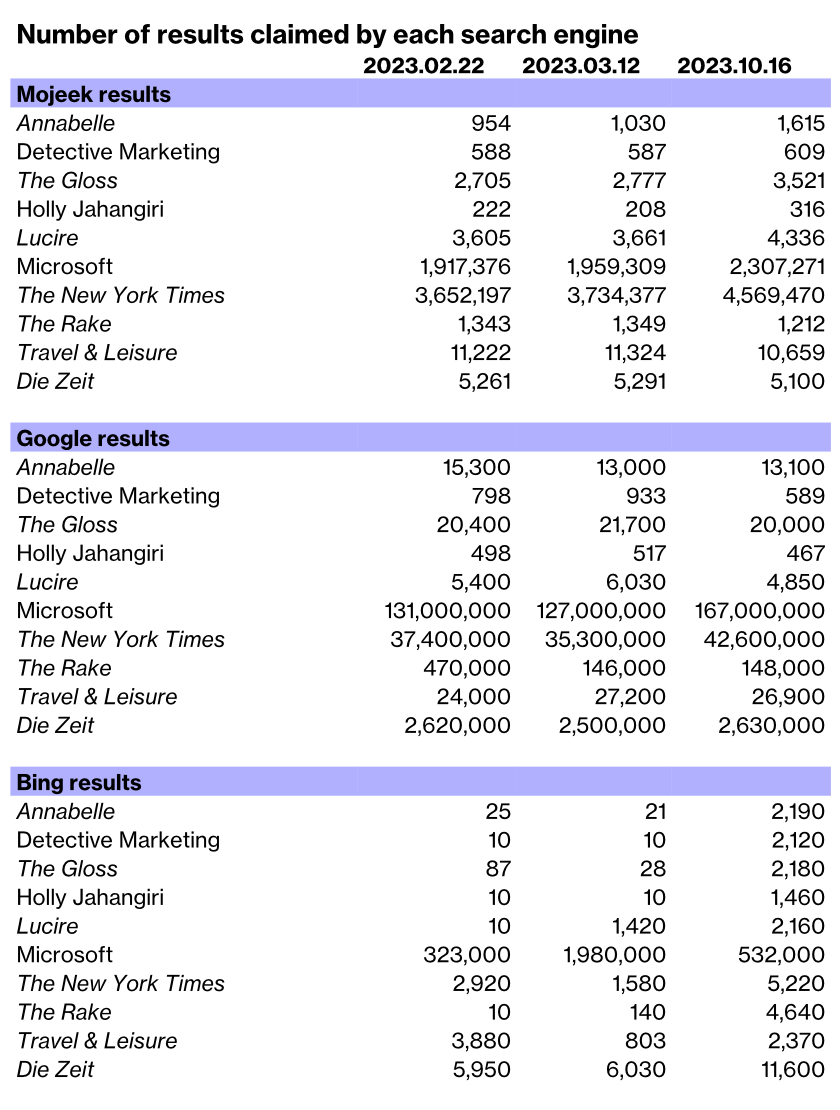
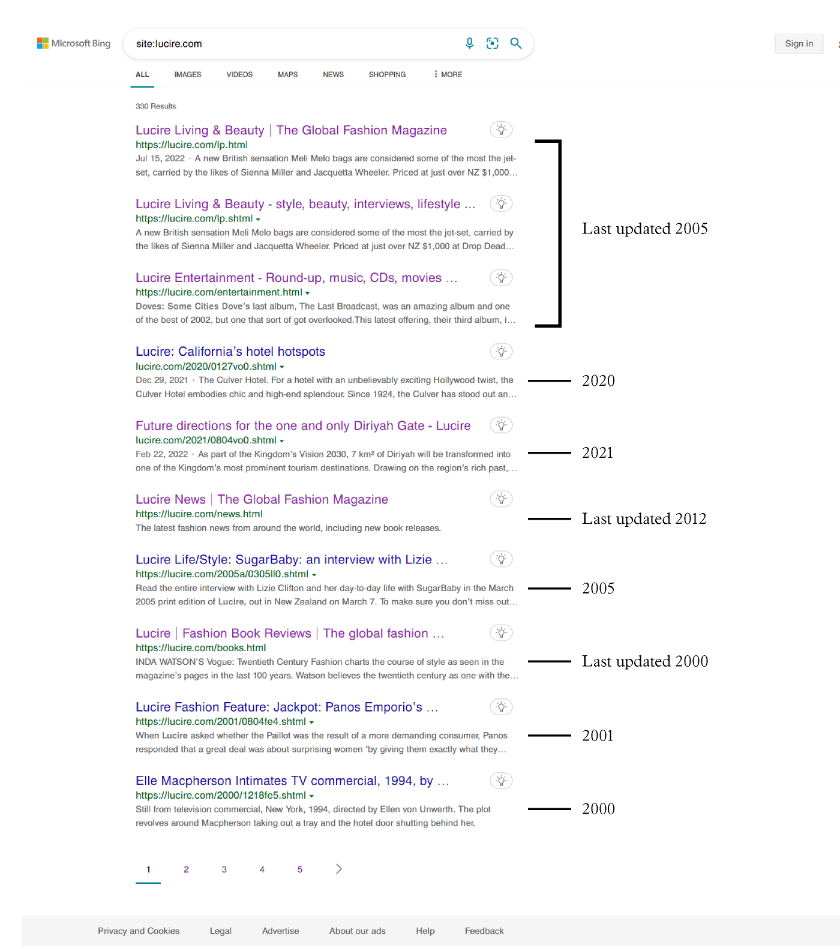
Bing is spidering new pages, as long as they’re very, very old.
Last week, we added a handful of Lucire pages from 1998 and 1999. An explanation is given here. And I’ve spotted at least two of those among Bing’s results when I do a site:lucire.com search.
As a couple of newer pages have also shown up, I doubt there’s any issue with the template; and the home page now also appears, too. But, by and large, Bing is Microsoft’s own Wayback Machine, and most of the Lucire results are from the 1990s and early 2000s.
It got me thinking: do the other search engines do this, too? For years, Google grandfathered older pages and they came up earlier. (Meanwhile, searches for my own name still have this site, and the company site, down, having lost first and second when we switched from HTTP to HTTPS in March. Contrary to expert opinion, you don’t recover, at least not quickly.)
As Lucire includes the date of the article in the URL, this should be an easy investigation. We’ll only do the first 50 results as that’s all Bing’s capable of. I’ll try not to include any repeat results out of fairness. ‘Contents’ pages’ include the home page, the Lucire TV and Lucire print shopping pages, and tag and category pages.
Bing
Contents’ pages ★★★
1997
1998
1999 ★★★★
2000 ★
2001 ★★★★★★★★
2002 ★★
2003 ★★★
2004 ★★★★
2005 ★★
2006
2007 ★★★
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018 ★
2019 ★
2020
2021
2022
Google
Contents’ pages ★★★★★★★★★★★★★
1997
1998
1999
2000
2001
2002 ★★
2003
2004 ★★
2005
2006
2007 ★
2008
2009
2010 ★
2011 ★★★
2012 ★
2013 ★★
2014 ★★★
2015 ★
2016 ★★
2017 ★
2018 ★★★
2019 ★★★
2020 ★★★★★★★
2021 ★
2022 ★★★★
Mojeek
Contents’ pages ★★★★★★
1997
1998
1999
2000
2001
2002
2003
2004 ★
2005
2006
2007
2008
2009 ★
2010 ★★
2011 ★★
2012 ★★★
2013 ★★★★
2014 ★★★
2015 ★★★★★
2016 ★★★★★★★
2017 ★★★★★★
2018 ★★★
2019 ★★★★
2020 ★★★
2021
2022
Baidu
Contents’ pages ★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018 ★
2019 ★
2020
2021 ★★★
2022 ★
Yandex
Contents’ pages ★★★★★
1997
1998
1999 ★★★★★
2000 ★★★★★★
2001 ★★★
2002 ★★★
2003 ★★★
2004 ★
2005
2006
2007 ★★★★
2008 ★★
2009 ★★
2010 ★★★★
2011 ★★★
2012 ★★
2013 ★
2014 ★★
2015
2016
2017
2018
2019
2020 ★★★
2021 ★
2022
To me, that was fascinating. My instincts weren’t wrong with Bing: it’s old and it favours the old (two of the restored articles were indexed). From the first 50 results, 18 results were repeats—that’s 36 per cent. I’m of the mind that Bing is so shot that it can only index old pages that don’t take up much space. New ones have a lot more data to them, generally.
Google does a good job with the top-level and second-level contents’ pages, though there were a few strange tag indices. But the distribution is what you’d expect: people would search for more recent stories. I know we had some popular stories from 2002 that still get hit a lot.
Mojeek has a similar distribution, though it should be noted that you can’t do a blanket site: search. There must be a keyword, and in this case it’s Lucire. The 2016 pages form the mode, which I don’t have a huge problem with; it’s better than the 2001 pages, which Bing has over everything else.
Baidu’s one is crazy as individual stories are seldom spat out in the first five pages, the search engine preferring tag indices, though half a dozen later story pages do make it into its top 50.
Finally, Yandex leans toward older pages, too, including our most popular 2002 piece. It’s the 2000 stories it has the most of among the top 50, and there’s a strange empty period between 2015 and 2019. But at least there is a fairer distribution than Bing can muster.
The other query that I had was whether these search engines were biasing their results toward HTML pages, rather than PHP ones. If that’s the case, then it could explain Bing’s preference for the old stuff (Lucire didn’t have PHP pages till 2008; prior to that it was all laboriously hand-coded, albeit within templates.)
Bing
★★★★★★★★★★★★★★★★★★★★★★★★★ HTML
★ PHP
Google
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ HTML
★★★★★★★★★ PHP
Mojeek
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ HTML
★★★★★★★★★★★★★★★★★ PHP
Baidu
★★★★★★★★★★ HTML
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ PHP
Yandex
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ HTML
★★★★★★ PHP
I think we can safely say there’s a preference for HTML over PHP. Mojeek brings up a lot of HTML pages after the top 50, even though this sample shows the split isn’t as severe.
Our PHP pages are less significant though: they contain news stories, and these are often ones other media covered, too. But I would have thought some of the more popular stories would have made the cut, and here it’s Mojeek’s distribution that looks superior to the others’. It seems like it’s actually analysing the page content’s text, which is what you want a search engine to do.
Baidu’s PHP-heaviness is down to all the tag indices—rendering it not particularly helpful as a search engine.
On these two tests, Mojeek and Google rank best, and Yandex comes in third. Baidu and Bing are a distant fourth and fifth.
You may also like