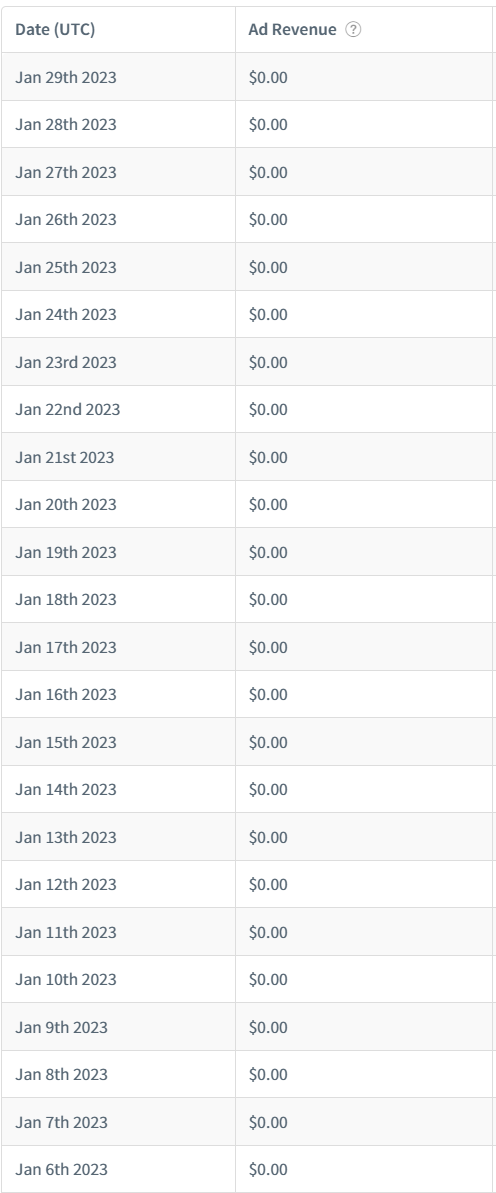
It’s going to be very interesting to see the legalities of Google using the contents of 15·1 million websites for its C4 dataset, used to train large language models. Ton Zijlstra put me on to a Washington Post article that revealed which sites were used. He had discovered that his own website (zylstra.org) had provided 200,000 tokens, ranked 102,860 of all the sites used. C4 has been used for Google’s T5 and Facebook’s LLaMA.
These sites included some highly questionable ones, including white supremacist and fascist ones, while religious sites lean toward the west.
I decided to feed ones I’m affiliated with into The Washington Post’s search.
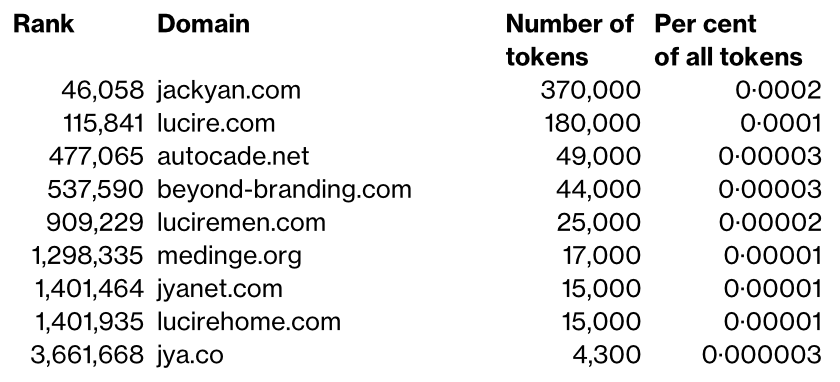
I wonder what the legalities are here. Is this a use of copyrighted content? There’s no doubt that the content is subject to copyright but it’s harder to figure out where the duplicate is. Google had to have a copy of the data though with which to train its program, as I doubt it would have trawled the web each time. The fact the old Lucire Home website is there, and not its successor Lucire Rouge, which came into being three years ago, tells me as much.
It exploited the copied content for monetary gain, unlike some of us who might save an article to our hard drive for later reading.
I’ll be very interested to how if any case law results from this unauthorized use of content. No one should acquiesce. No wonder Google wouldn’t help us deal with a pirate—they were only doing what Google did, storing a version of our site on its own server.
You may also like